




2022年10月17-21日,第28屆ACM移動計算與通訊系統(tǒng)大會(MobiCom 2022,CCFA類)在澳大利亞悉尼舉行。計算機學院系統(tǒng)軟件團隊關于泛在計算環(huán)境下的利用異構計算資源進行端側原位訓練的論文“Mandheling:Mixed-Precision On-Device DNN Training with DSP Offloading”進行了在線匯報,得到了與會者的高度關注和廣泛討論。
論文圖示
在泛在計算環(huán)境下,智能化已經成為系統(tǒng)軟件的重要基本特征之一,實現智能化的主要途徑是訓練出高質量的機器學習模型。近年來,相對于在云計算和數據中心上的大規(guī)模模型訓練,在移動設備本地來訓練深度神經網絡模型(DNN),即端側或邊緣側的設備上的原位訓練模式(On-DeviceTraining)得到了學術界和工業(yè)界的關注。原位訓練模式在數據安全隱私保護、網絡連接不穩(wěn)定、惡劣物理環(huán)境等場景下的智能任務有其特殊的應用優(yōu)勢,主流的深度學習框架如谷歌的TensorFlow、阿里的MNN均對端側的DNN訓練提供了支持。
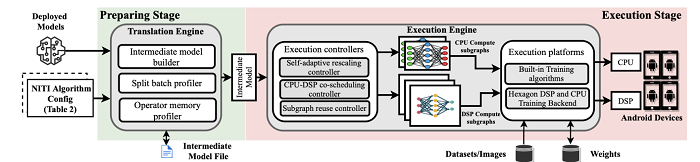
端側原位訓練的主要挑戰(zhàn)之一在于端設備資源能力受限。不同于傳統(tǒng)方法主要利用CPU和GPU等計算資源,本文提出了對端側重要的異構計算資源—數字信號處理器(Digital Signal Processor)進行軟件定義以支持混合精度訓練的分載技術及系統(tǒng)Mandheling。一方面,傳統(tǒng)的DNN訓練主要在FP32數據格式上執(zhí)行,但近期研究發(fā)現,一些混合精度算法生成的權重和激活若用INT8和INT16等低精度數據格式表示,能夠有效降低訓練時間資源成本,同時保證收斂精度,如在CIFAR-10上僅損失1.3%。而另一方面,DSP特別適合整數運算,比如INT8矩陣乘法,Hexagon 698 DSP足以在一個周期內執(zhí)行128次INT8操作。
Mandheling基于“軟件定義”的思路,提出了四項創(chuàng)新技術充分發(fā)揮了DSP在整數計算中的優(yōu)勢以支持混合精度模型的高效原位訓練:(1)提出CPU-DSP協(xié)同調度策略以減輕對DSP不友好的算子的開銷;(2)提出自適應重伸縮rescaling算法減少反向傳播dynamicrescaling的開銷;(3)提出batch-splitting算法來提高DSP緩存效率;(4)提出DSP計算子圖復用機制以消除DSP上的準備開銷。實驗結果表明,與TFLite和MNN兩個SOTA的端側DNN訓練引擎相比,Mandheling將每個批(batch)的訓練時間平均減少了5.5倍,能耗平均減少了8.9倍。在端到端訓練任務中,與FP32精度的baseline相比,Mandheling將收斂時間提升了10.7倍,同時能耗降低13.1倍,模型準確率損失僅為2%。
本文的第一作者為2021級博士生徐大亮,指導教師為劉譞哲研究員。值得一提的是,該課題組是國際上最早研究泛在計算環(huán)境下原位訓練智能系統(tǒng)的團隊之一,成果已經連續(xù)發(fā)表在MobiCom 2018、WWW 2019(中國學者首個WWW最佳論文獎)、MobiSys 2020、WWW 2021、MobiSys 2022等頂級會議上,在與國家電網、中國鐵道、KikaTech等的合作中產生了積極的應用效果和影響。
ACM MobiCom是計算機網絡系統(tǒng)的頂級學術會議,也是CCF推薦的A類會議。MobiCom 2022收到了314篇投稿,錄用56篇,錄用率為18%。