




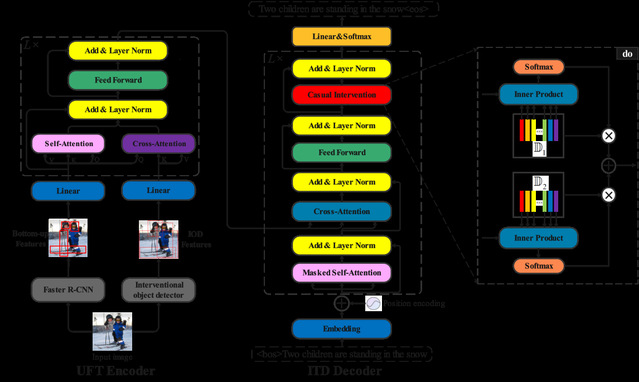

圖像描述自動生成因果推理模型框架圖
當前,以深層神經網絡為基礎框架的深度學習方法成為人工智能領域的主流學習范式。然而,由于深度學習的黑盒映射特性,大量深層網絡模型的學習結果難以解釋和信任。問題的根源在于傳統深度學習方法僅局限于關聯關系學習,關注輸入與輸出數據間的相關性,而忽略了兩者間的因果關系發現,導致模型在測試集分布發生變化、樣本分布不平衡和小樣本條件下性能嚴重退化。將因果推理引入深度學習領域,賦予深層網絡模型主動因果干預和因果關系學習能力,是解決這一難題的有效途徑,也是構建強人工智能學習方法的重要基礎。
近日,計算機科學與技術學院人工智能與計算機視覺課題組劉兵副教授、王棟碩士研究生和周勇教授在該領域取得研究進展,將因果推理引入圖像描述自動生成領域,賦予機器在“看圖說話”過程中的因果推理能力。研究成果形成論文“Show, Deconfound and Tell: Image Captioning with Causal Inference”,以中國礦業大學為第一單位,劉兵副教授為第一作者,發表在計算機領域頂級國際會議2022 IEEE Conference on Computer Vision and Pattern Recognition(CVPR)。
為了消除傳統圖像描述深層模型中圖像與文本間的虛假關聯,該論文引入因果圖外部知識,通過揭示視覺域與語言域混淆機理,在目標檢測和描述生成中同時進行因果干預,阻斷圖像視覺特征與描述文本之間的后門路徑。在理論分析基礎上,設計了目標檢測和描述生成因果干預網絡,將因果推理與深度網絡無縫融合,實現了圖像描述生成中的因果關系學習。實驗結果表明,所提方法能夠在圖像描述生成中進行因果推理,獲得了當前最優的圖像描述生成性能。
CVPR是由IEEE舉辦的計算機視覺領域三大頂級國際會議之一,被中國計算機學會(CCF)推薦為計算機學科領域A類國際會議。